
Impieghiamo queste giornate dal tempo deformato per presentare i lavori che ci vedono impegnati nel nostro laboratorio casalingo. Il tema di oggi è collegato a progetti in corso, basati sulla Visione Artificiale.
La visione artificiale (Computer vision) si occupa di come i computer possono ottenere una comprensione di alto livello da immagini o video digitali. E’ una scienza intrerdisciplinare volta a comprendere e automatizzare i compiti che il sistema visivo umano può svolgere. Vi sono numerose applicazioni, in ambito industriale e non. Ad esempio:
– Lettura di caratteri e codici (vedi autovelox o telecamere ZTL);
– Classificazioni;
– Guida di robot;
– Controllo veicoli autonomi;
– Videosorveglianza;
– Modellizzazioni di oggetti o ambienti.
Oltre all’analisi delle immagini, ciò che rende interessante questo campo sono le fasi successive ovvero l’Analisi dei dati (Data analytics) e l’Apprendimento automatico (Machine Learning). L’intervento sui dati grezzi viene effettuato per trarne informazioni utili, con l’impiego di algoritmi, in relazione agli impieghi successivi. Sempre attraverso algoritmi, un computer può apprendere e adattarsi a nuovi dati senza interferenze umane e questa è l’idea attuale di Apprendimento automatico (Machine learning) è il concetto secondo cui un programma per. Data analytics e Machine learning sono discipline che si muovono nel campo dell’Intelligenza Artificiale (Artificial Intelligence).
L’idea di una “intelligenza artificiale” (nome affascinante per dire tantissima matematica :-D) ha una lunga storia, ma in tempi moderni ha subito un’accelerazione a partire dal 1950 ed il termine Artificial Intelligence è stato coniato nel 1956 da John McCarthy (questa informazione può esser utile per le parole incrociate), professore di Computer Science alla Standford University.
Con l’intelligenza artificiale si fece spazio l’idea di realizzare una rete simile a quella dei neuroni biologici. e questa idea maturò in quegli anni in Warren McCulloch e Walter Pitts al Massachusetts Institute of Technology che progettarono una Rete Neurale Artificiale (Artificial Neural Network), utilizzando delle porte logiche. Negli anni ’60 Frank Rosenblatt, psicologo americano, realizzò il perceptron, un dispositivo elettronico costruito secondo i principi biologici, che mostrò una capacità di apprendimento. Il suo lavoro venne eseguito impiegando un mainframe IBM 704, amichevolmente conosciuto come “big iron“, un soprannome che dà l’idea dell’ingombro.
Le RNA sono costruite distinguendo tre livelli: INPUT – HIDDEN – OUTPUT, costituite da elementi che potrebbero essere paragonati ai Neuroni. Analogamente al cervello umano, la conoscenza non risiede nei singoli neuroni, ma è distribuita tra neuroni, collegati tra di loro attraverso le Sinapsi. Pertanto, la presenza di collegamenti e l’intensità di questi collegamenti si affina grazie all’esperienza che ci permette, con un grado di probabilità sempre più elevato nel tempo, di collegare elementi percepiti a determinate situazioni. E ci porta anche, in presenza di elementi diversi rispetto al solito, a formulare ipotesi per condurli ad un quadro plausibile di eventi, ai quali assegniamo un diverso grado di probabilità. Possiamo dunque distinguere una fase di apprendimento, una fase di validazione e una fase di generalizzazione.
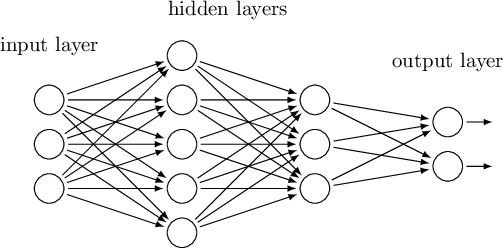
Le RNA vengono costruite stabilendo il numero di neuroni in Input e in Output e provando varie soluzioni sul numero di neuroni nel livello Hidden, in base alle prestazioni della Rete.
Le prestazioni si valutano in relazione alla capacità di discriminare passando da elementi noti a situazioni non note. E si tratta di bilanciare livello di precisione con capacità di generalizzazione. Se una rete viene allenata con un certo pattern di INPUT e OUTPUT, saprà esprimersi con un’elevata precisione ogni volta che le verrà presentato un caso che rientra nel set usato per l’apprendimento. Tuttavia, nel momento in cui le fossero presentati dei casi che differiscono per qualche dato rispetto ai primi, potrebbe non essere in grado di ricondurli alle categorie di Output sulle quali è stata allenata. Quindi più elevate sono la varietà e la numerosità dei casi scelti per l’allenamento ed il numero di cicli di allenamento, meglio sarà in termini di prestazioni su casi ignoti. Anche il numero di livelli e di neuroni Hidden condiziona le performance delal RNA. L’allenamento modifica l’intensità dei legami tra i neuroni artificiali e permette alla RNA di migliorare le proprie prestazioni.
Le RNA apprendono seguendo un percorso simile all’apprendimento umano, in un percorso continuo, fatto di azioni e retroazioni, fino a che non si acquisisce padronanza di una tecnica, di un comportamento, di un testo. Le RNA dapprima vengono addestrate in modo da collegare INPUT noti ad OUTPUT noti. In un secondo tempo si procede ad una fase di Test o validazione cioè si chiede alla Rete di valutare elementi che non ha “visto” nella fase di addestramento, ma che sono noti agli sperimentatori. Applicazioni di questo genere sono tipiche dei problemi di classificazione, quando l’interesse è rivolto ad identificare le variabili che maggiormente determinano l’appartenenza ad una categoria piuttosto che ad un’altra.
Dagli anni ’60 agli anni ’80 si registra una fermata degli studi in questo campo. Poi, dall’inizio degli anni ’90, grazie alla diffusione dei primi personal computer con chip sempre più veloci e con l’invenzione di nuovi linguaggi di programmazione, l’intelligenza artificiale venne applicata per risolvere problemi ancora complessi, come l’interpretazione del linguaggio naturale, il riconoscimento visivo delle immagini e la rappresentazione generale della realtà.
Come esempio, si potrebbe considerare l’articolo “Characterisation of White Vinegars of Different Sources with Artificial Neural Networks“, scritto nel 1998 da Vincenzo Gerbi, Giuseppe Zeppa, Riccardo Beltramo, Alberta Carnacini e Andrea Antonelli. In quel lavoro, mettemmo in relazione parametri chimici e sensoriali con le materie prime utilizzate per fabbricare l’aceto (vino, mele, alcool) e valutammo le capacità di classificazione delle RNA in relazione all’importanza delle variabili in INPUT.
Oggi l’effetto sinergico determinato dalla disponibilità di componenti elettronici, dai linguaggi di programmazione software (opensource), dalla riduzione dei costi mettono a disposizione degli smanettoni (hacker) ciò che serve per realizzare delle vere e proprie applicazioni dell’Intelligenza Artificiale home made. L’introduzione ci fa apprezzare il contributo che l’innovazione tecnologica ha dato all’impiego di questi strumenti. Si pensi a come cambia il livello di difficoltà quando si passa da problemi classificatori che comprendono una ventina di variabili a quelli legati al riconoscimento di immagini, le cui variabili sono rappresentate dalle migliaia di pixel di cui è composta un’immagine. Oggi le fasi di addestramento le troviamo condensate in librerie informatiche le quali, opportunamente richiamate nei programmi, ci risparmiano la fatica di tentativi per addestrare le reti che operano in background nei programmi di Visione artificiale.
Ed allora torniamo alla Visione Artificiale e agli interessi scatolottiani in materia, che riprenderemo nella prossima puntata. Mentre noi prendiamo taccuino e pennarelli per progettare il contenitore di un sistema di visione artificiale, vi invitiamo a consultare i divertenti esperimenti che si possono realizzare con Raspberry Pi e il camera module.
Dopo aver eseguito l’Installazione ed esplorato le funzioni, numerosi blog accompagnano gli sperimentatori nella realizzazione di sistemi di videosorveglianza, di identificazione di oggetti, di modellizzazione di oggetti o ambienti.



